
Connecting Distributed SCADA with NATS.io (Part Two)
David Gee
Posted on Mar 10th, 2023
This is part two of the Distributed SCADA with NATS.io series of blog posts. In the previous post, we discussed the basics of SCADA and proposed a distributed SCADA model that meets modern demands head on.
NATS.io to the Rescue
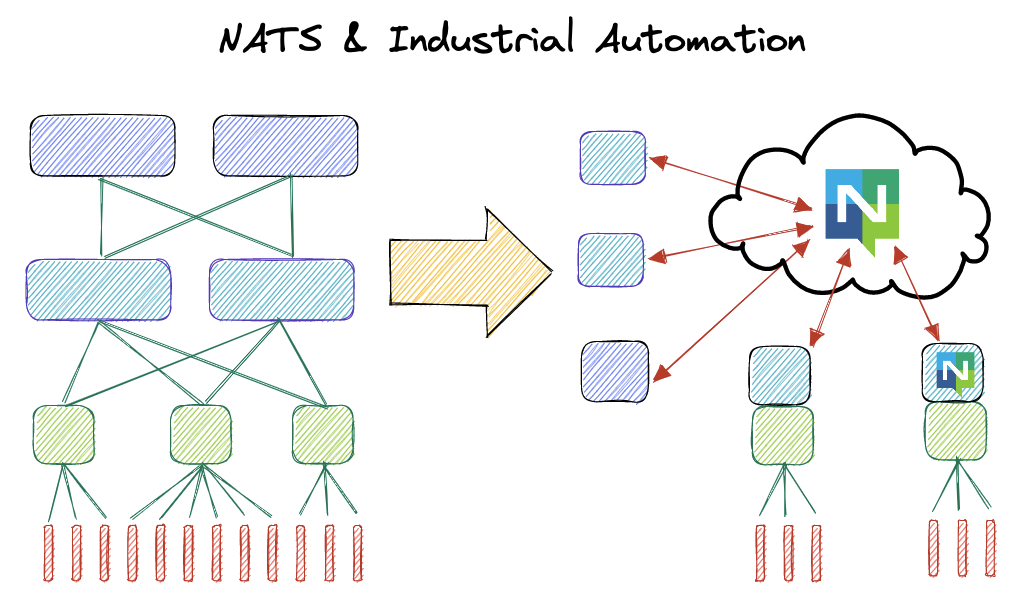
The wider the SCADA system is, the more distributed it becomes, the harder it is to securely connect and operate. A closely bound system might be able to operate with centralised decision making and state-machine style mimics, but a widely distributed system with many components becomes a matter of heuristics and distributed state-machine process handling. To word it a different way, we move from a synchronous, tightly time bound system, to one that's event-driven, asynchronous and with headless anomaly detection and operational control. Due to tight control requirements of any automated process, the real-time control points like PLCs must remain in close proximity to the process hardware they interact with and so it must be rethought how to connect to, pull information from and control these islands of automation by Level 2 and above of the classic SCADA architecture.
Noteworthy points
- Wide Area Network (WAN) links are expensive and the internet is cheap
- The internet is unreliable and considered hostile
- Extending enterprise IP networks is complex and increases security risks
- PLC interfaces are arcane, insecure to obscure controls and are resource constrained
- PLCs are not general units of compute, but fixed, real-time systems without virtual memory (as always, it depends on manufacturer), meaning they're not flexible like Linux
- Systems that interact with PLCs ideally must be in close proximity, are carefully gated and all systems are configured based on Zero Trust principles
Let's start by rethinking the SCADA diagram. We want a secure connective substrate between the Level 1 and Level 2 systems. This substrate trusts nothing by default and requires each system that accesses it to have an authentication and authorisation token.

The diagram above shows two component types of Level 1.5. Both Client and Node components can communicate with PLC systems in an abstracted fashion, removing the headache of handling different data units and the address based locations of data. Both clients also initiate communications to the PLCs and to NATS, easing communications through firewalls and removing location headaches and the reliance on privately or publicly routable IP addresses.
Data Fabric Client (C)
Has relevant configuration to subscribe to meaningful command and control conversations, as well as publish data that is of interest for Level 2 and above systems. It will transmit state changes and measurements of interest. This component is useful in small remote deployments.
Data Fabric Node (N)
Same as the client above, with the addition of a local NATS server running as a leaf node. This leaf node can provide continued NATS functionality in the event of a WAN disconnect event and also house local streams, sourced from data published to NATS subjects.
Both of these components inherit zero trust principles and require both authentication and authorisation to the NATS network and they can provide both rate-limiting and permit-list handling of control messages, further protecting the Level 1 devices.
Core NATS in this scenario replaces MQTT and can provide high performance subject based messaging for request/reply and publish/subscribe semantics, meaning it's great as a communications broker that transports messages between connected components. Because NATS has an MQTT integration, any Level 1 components that are enabled with MQTT can also connect to NATS without requiring any special treatment.
When NATS is configured with JetStream its persistence layer, in this scenario NATS replaces Kafka. It acts as a streaming system and stores messages with a sequence number and when you use durable consumers, a feature of NATS, if your consuming software disconnects, it can carry on where it left off. Filtering subscriptions and streams is easy too because NATS is based on subject based naming, meaning you can subscribe granularly to subject names, like foo.bar.baz or just foo.*.
Regarding network connectivity, few to no network modifications need to be made:
- NATS is based on unicast IPv4 or IPv6. No multicast, IGMP or weird networking requirements
- NATS clients initiate a connection to the server
- NATS servers when clustered initiate full mesh unicast connections to each other
- Islands of NATS clusters connect to each other through gateways, in which one gateway connection per cluster is made
- NATS leaf nodes initiate a connection to a server (just like NATS client code)
- NATS has TLS capabilities built right in, so NATS can work without encrypted VPN tunnels
When distributed authentication and authorisation is configured, each connection above can be authenticated with JWTs, a PKI system called nkey, or your own in-house system. Authorisation is also possible through the use of JWTs. NATS in this mode is called decentralised auth, in which each application or process will be mapped to a NATS account and each connection is mapped to a NATS user.
Below shows how a real-world scenario might look based on this model.

Classic Level 2 to Level 4 can be assumed to be on an enterprise network and extending NATS between on-premises data centers to public cloud or to the edge is as easy as it looks above.
Zero Trust Data Fabric
Multiple aspects exist when discussing zero trust for NATS. A NATS cluster can authenticate at the connection level and will transparently bridge communications between different accounts and user connections on the same system. NATS for these scenarios is split into four sections.
NATS Cluster Connectivity
Clusters are authenticated at the connection level and communicate bidirectionally.
NATS Operator
This is the configuration at an operational level for the whole NATS cluster. A NATS operator mints account tokens and has credentials to monitor and operate the entire cluster.
NATS Accounts
These are minted by the operator system and accounts are analogous to applications. Each SCADA application could have an account and accounts can share data between each other by explicit import and export configuration. Accounts create user tokens.
NATS Users
These are analogous to application connections. Each connection therefore has an authentication token and is authorised to engage on specific actions and subjects. A Level 1.5 client will be configured with a NATS user token, which grants it access. When each client connects to NATS, it only needs to know about one or two connections and by the magic of the Gossip protocol, it becomes aware of all of the available points of connectivity.
Zero Trust Computer Networks
For completeness, another important aspect to consider is a prescriptive network configuration for every point of connectivity. Each device, whether PLC, supervisory machine, HMI and anything else connecting to an Ethernet and IP network has a MAC address. Network access should be limited to known MAC addresses and the network should report any unknown MAC addresses attempting to connect before shutting down physical ports that are disconnected or are in error state. Measures should be deployed to administratively shut down Ethernet ports should they be disconnected out of a maintenance window and bubble up alerts to operations engineers who can manage situations accordingly. Protocols like 802.1x help with network access control, but few industrial devices seem to support it.
Summary
In this post, we’ve covered a data fabric architecture with NATS and the network requirements of this ubiquitous data fabric solution. We also covered some high-level thoughts on zero-trust networking.
Part three, the final post of this mini-series will discuss the real-world implications of a Zero Trust Level 1.5 Data Fabric Layer.