
NATS Weekly #26
Byron Ruth
Published on May 16th, 2022

Week of May 9 - 15, 2022
🗞 Announcements, writings, and projects
A short list of announcements, blog posts, projects updates and other news.
⚡Releases
Official releases from NATS repos and others in the ecosystem.
- nats-io/nats.rs - v0.20.0
- nats-io/nats.ex - v1.5.1
- nats-io/k8s - nats-v0.17.0, nack-v0.14.0
- nats-io/nats-top - v0.5.2
- nats-io/nats-rest-config-proxy - v0.7.0
💬 Discussions
Github Discussions from various NATS repositories.
- nats-io/nats-server - Consumer payload-based filtering
- nats-io/nats.go - Encoder.Decode() doesn't seem to be passing along the nats-headers of the message - just the subject and the data
💡 Recently asked questions
Questions sourced from Slack, Twitter, or individuals. Responses and examples are in my own words, unless otherwise noted.
How can I spin-up a server for testing?
There is a hidden gem in the NATS CLI which allows you to run a NATS server for development or testing purposes.
nats server run --jetstream
This will generate a temporary config file based on the CLI options you specify. It automatically creates two accounts, USER and SERVICE and exports and imports the service.> subject to the USER account. Both have generated credentials that are printed out on startup, for example:
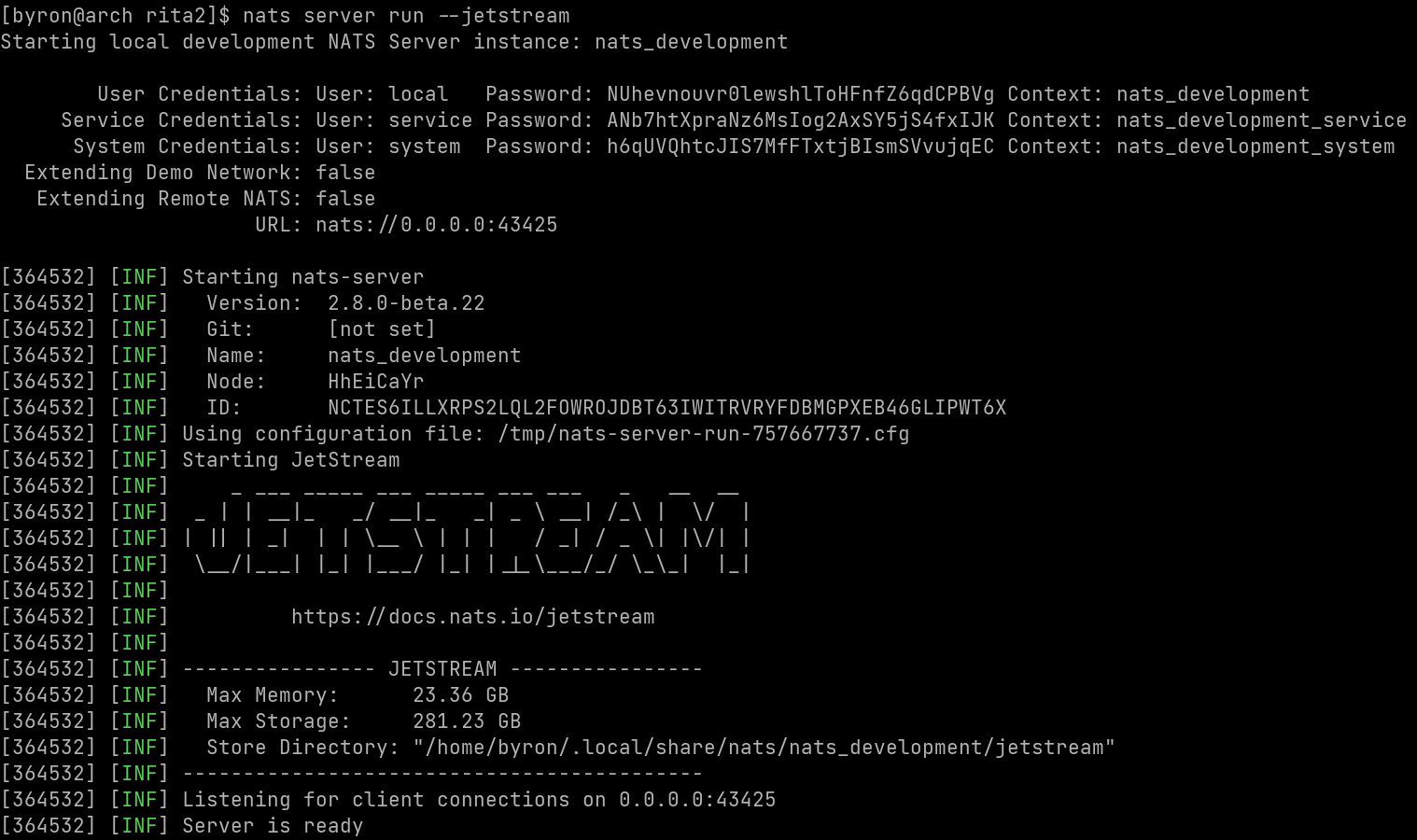
Note the credentials, NATS URL (with a random port) and the path to the configuration file is all present to inspect.
At this point, you can use the NATS CLI (or customer application) to use the service creds to provide some service and the user creds to connect and consume the service.
Two additional notable options to this command are --extend and --extend-demo which generates additional configuration to connect this ephemeral server as a leaf node to an existing cluster or the NATS demo cluster, respectively.
How does a mirror behave when a message is deleted or a purge occurs on the source stream?
NATS has support for asynchronous data replication where a stream can act as a mirror of a stream or, more generally, a stream can be configured to source messages from one or more streams (in addition to its own messages). A mirror can be thought of as a specialization of the multi-stream sourcing case.
A notable feature of either of these setups is that the target stream can be configured with a different retention policy and replication factor than the sources. For example, the source stream may be considered as an interest-based stream which means that once all consumers ack a message in that stream, it is deleted. If we create a mirror for the purpose of archiving these messages in long-term storage, we can configure the mirror to be limits-based so the message is not deleted based on interest.
Note that a mirror on a work-queue-based retention policy will act as a typical consumer and will ack and dequeue the message. As designed this makes sense, but my intuition assumed mirrors would have been a special case not behaving like typical consumers (since the use case is replication and not processing the work). In other words, I had assumed a mirror would copy the message, but it would be left in the queue for an actual worker to pick it up..
In either case, there are manual operations such as message deletion and stream purging that can be performed at any time. So the question is, what happens if a message is published to a source stream followed by a delete or purge operation?
As currently implemented, if either of operations are accepted by the server prior to a message being replicated (and the message is affected in the operation), the replica would not observe that message. This is technically a race condition (i.e. which operation will happen first), but that is the nature of asynchronous behavior.
Stepping back, it is important to think about the intent underlying the message delete or stream purge. It may be the case that there is a privacy concern and a stream is being purged of some user's data. In that case, we wouldn't want the data to replicate further in the system (although all streams would need to be inspected regardless).
The second intent may operational, such as a stream or a specific subject in the stream is getting too large or there is a corrupt message, etc. In this case, the source stream needs to be acted on, but it still may be desirable to have, say, and archival stream mirror to get everything. In this case, if messages are deleted prior to replicating, then those won't make it in the archival stream.
One final note is that this fuzziness on behavior applies to ad-hoc operations and not the general behavior of the retention policy. For example, a stream can be pre-configured to prune messages after some age. Those auto-purge operations would occur after the known set of mirrors (and sourcing streams) received the message if applicable.
What is the appropriate AWS EBS volume to store JetStream data?
This was an announcement by Todd Beets in Slack that I thought was worth repeating.
If you are encountering unanticipated JetStream leader changes in your cluster, especially under high-pressure loadings, and you are hosting on AWS and using EBS storage for your JetStream state, double-check that your EBS type (e.g. gp2, io1, io2) and configured base IOPS throughput is sufficient for your workload. This would include k8s environments hosted on AWS and using EBS storage underneath the covers of course.Working with some implementers with stress-test JetStream configurations, default (gp2) EBS storage may not be sufficient filesystem performance, especially in EBS configuration that allows peak IOPS for 30 minutes in a 24 hour window and does a throttle/penalty-box action on your instance throughput.
In other words, ensure you stress test the storage you intend to use during development to ensure the provisioned IOPS are sufficient and your application won't be throttled at peak workloads.